
文章目录[+]
不知道你在生活中是否留意过这样的现象:我们可以根据相貌轻易区分出日本人、韩国人和泰国人,却对英国人、俄罗斯人和德国人脸盲。造成这种现象的原因一方面在于日韩泰都是我国的邻国,观察这些国家普通人的机会较多;另一方面,抛开衣妆的因素不论,相同的人种也使得面貌特征更加容易进行比较和辨别。因此,根据大量的观察就能总结出不同国别的相貌特点:中国人下颌适中,日本人长脸长鼻,韩国人眼小颧高,泰国人肤色暗深。在做出路人甲来自日本或是路人乙来自韩国的判断时,正是以这些特征作为依据的。上面的例子就是简化版的人类学习机制:从大量现象中提取反复出现的规律与模式。这一过程在人工智能中的实现就是机器学习。
从形式化角度定义,如果算法利用某些经验使自身在特定任务类上的性能得到改善,就可以说该算法实现了机器学习。而从方法论的角度看,机器学习是计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的学科。机器学习可说是从数据中来,到数据中去。假设已有数据具有一定的统计特性,则不同的数据可以视为满足独立同分布的样本。机器学习要做的就是根据已有的训练数据推导出描述所有数据的模型,并根据得出的模型实现对未知的测试数据的最优预测。
在机器学习中,数据并非通常意义上的数量值,而是对于对象某些性质的描述。被描述的性质叫作属性,属性的取值称为属性值,不同的属性值有序排列得到的向量就是数据,也叫实例。在文首的例子中,黄种人相貌特征的典型属性便包括肤色、眼睛大小、鼻子长短、颧骨高度。标准的中国人实例甲就是属性值{浅、大、短、低 }的组合,标准的韩国人实例乙则是属性值{浅、小、长、高}的组合。
根据线性代数的知识,数据的不同属性之间可以视为相互独立,因而每个属性都代表了一个不同的维度,这些维度共同张成了特征空间。每一组属性值的集合都是这个空间中的一个点,因而每个实例都可以视为特征空间中的一个向量,即特征向量。
需要注意的是这里的特征向量不是和特征值对应的那个概念,而是指特征空间中的向量。根据特征向量对输入数据进行分类就能够得到输出。在前面的例子中,输入数据是一个人的相貌特征,输出数据就是中国人 / 日本人 / 韩国人 / 泰国人四中选一。而在实际的机器学习任务中,输出的形式可能更加复杂。根据输入输出类型的不同,预测问题可以分为以下三类。
分类问题:输出变量为有限个离散变量,当个数为 2 时即为最简单的二分类问题;回归问题:输入变量和输出变量均为连续变量;标注问题:输入变量和输出变量均为变量序列。
但在实际生活中,每个国家的人都不是同一个模子刻出来的,其长相自然也会千差万别,因而一个浓眉大眼的韩国人可能被误认为中国人,一个肤色较深的日本人也可能被误认为泰国人。
同样的问题在机器学习中也会存在。一个算法既不可能和所有训练数据符合得分毫不差,也不可能对所有测试数据预测得精确无误。因而误差性能就成为机器学习的重要指标之一。在机器学习中,误差被定义为学习器的实际预测输出与样本真实输出之间的差异。在分类问题中,常用的误差函数是错误率,即分类错误的样本占全部样本的比例。误差可以进一步分为训练误差和测试误差两类。训练误差指的是学习器在训练数据集上的误差,也称经验误差;测试误差指的是学习器在新样本上的误差,也称泛化误差。
训练误差描述的是输入属性与输出分类之间的相关性,能够判定给定的问题是不是一个容易学习的问题。测试误差则反映了学习器对未知的测试数据集的预测能力,是机器学习中的重要概念。实用的学习器都是测试误差较低,即在新样本上表现较好的学习器。学习器依赖已知数据对真实情况进行拟合,即由学习器得到的模型要尽可能逼近真实模型,因此要在训练数据集中尽可能提取出适用于所有未知数据的普适规律。然而,一旦过于看重训练误差,一味追求预测规律与训练数据的符合程度,就会把训练样本自身的一些非普适特性误认为所有数据的普遍性质,从而导致学习器泛化能力的下降。
在前面的例子中,如果接触的外国人较少,从没见过双眼皮的韩国人,思维中就难免出现“单眼皮都是韩国人”的错误定式,这就是典型的过拟合现象,把训练数据的特征错当做整体的特征。
过拟合出现的原因通常是学习时模型包含的参数过多,从而导致训练误差较低但测试误差较高。与过拟合对应的是欠拟合。如果说造成过拟合的原因是学习能力太强,造成欠拟合的原因就是学习能力太弱,以致于训练数据的基本性质都没能学到。如果学习器的能力不足,甚至会把黑猩猩的图像误认为人,这就是欠拟合的后果。
在实际的机器学习中,欠拟合可以通过改进学习器的算法克服,但过拟合却无法避免,只能尽量降低其影响。由于训练样本的数量有限,因而具有有限个参数的模型就足以将所有训练样本纳入其中。可模型的参数越多,能与这个模型精确相符的数据也就越少,将这样的模型运用到无穷的未知数据当中,过拟合的出现便不可避免。更何况训练样本本身还可能包含一些噪声,这些随机的噪声又会给模型的精确性带来额外的误差。
整体来说,测试误差与模型复杂度之间呈现的是抛物线的关系。当模型复杂度较低时,测试误差较高;随着模型复杂度的增加,测试误差将逐渐下降并达到最小值;之后当模型复杂度继续上升时,测试误差会随之增加,对应着过拟合的发生。在模型选择中,为了对测试误差做出更加精确的估计,一种广泛使用的方法是交叉验证。交叉验证思想在于重复利用有限的训练样本,通过将数据切分成若干子集,让不同的子集分别组成训练集与测试集,并在此基础上反复进行训练、测试和模型选择,达到最优效果。
如果将训练数据集分成 10 个子集 D1−10 进行交叉验证,则需要对每个模型进行 10 轮训练,其中第 1 轮使用的训练集为 D2~D10 这 9 个子集,训练出的学习器在子集 D1 上进行测试;第 2 轮使用的训练集为 D1 和 D3~D10 这 9 个子集,训练出的学习器在子集 D2 上进行测试。依此类推,当模型在 10 个子集全部完成测试后,其性能就是 10 次测试结果的均值。不同模型中平均测试误差最小的模型也就是最优模型。
除了算法本身,参数的取值也是影响模型性能的重要因素,同样的学习算法在不同的参数配置下,得到的模型性能会出现显著的差异。因此,调参,也就是对算法参数进行设定,是机器学习中重要的工程问题,这一点在今天的神经网络与深度学习中体现得尤为明显。假设一个神经网络中包含 1000 个参数,每个参数又有 10 种可能的取值,对于每一组训练 / 测试集就有 100010 个模型需要考察,因而在调参过程中,一个主要的问题就是性能和效率之间的折中。
在人类的学习中,有的人可能有高人指点,有的人则是无师自通。在机器学习中也有类似的分类。根据训练数据是否具有标签信息,可以将机器学习的任务分成以下三类。监督学习:基于已知类别的训练数据进行学习;无监督学习:基于未知类别的训练数据进行学习;半监督学习:同时使用已知类别和未知类别的训练数据进行学习。
受学习方式的影响,效果较好的学习算法执行的都是监督学习的任务。即使号称自学成才、完全脱离了对棋谱依赖的 AlphaGo Zero,其训练过程也要受围棋胜负规则的限制,因而也脱不开监督学习的范畴。监督学习假定训练数据满足独立同分布的条件,并根据训练数据学习出一个由输入到输出的映射模型。反映这一映射关系的模型可能有无数种,所有模型共同构成了假设空间。监督学习的任务就是在假设空间中根据特定的误差准则找到最优的模型。
根据学习方法的不同,监督学习可以分为生成方法与判别方法两类。生成方法是根据输入数据和输出数据之间的联合概率分布确定条件概率分布 P(Y∣X),这种方法表示了输入 X 与输出 Y 之间的生成关系;判别方法则直接学习条件概率分布 P(Y∣X) 或决策函数 f(X),这种方法表示了根据输入 X 得出输出 Y 的预测方法。两相对比,生成方法具有更快的收敛速度和更广的应用范围,判别方法则具有更高的准确率和更简单的使用方式。
数学中的线性模型可谓“简约而不简单”:它既能体现出重要的基本思想,又能构造出功能更加强大的非线性模型。在机器学习领域,线性回归就是这样一类基本的任务,它应用了一系列影响深远的数学工具。在数理统计中,回归分析是确定多种变量间相互依赖的定量关系的方法。线性回归假设输出变量是若干输入变量的线性组合,并根据这一关系求解线性组合中的最优系数。在众多回归分析的方法里,线性回归模型最易于拟合,其估计结果的统计特性也更容易确定,因而得到广泛应用。而在机器学习中,回归问题隐含了输入变量和输出变量均可连续取值的前提,因而利用线性回归模型可以对任意输入给出对输出的估计。
1875 年,从事遗传问题研究的英国统计学家弗朗西斯·高尔顿正在寻找父代与子代身高之间的关系。在分析了 1078 对父子的身高数据后,他发现这些数据的散点图大致呈直线状态,即父亲的身高和儿子的身高呈正相关关系。而在正相关关系背后还隐藏着另外一个现象:矮个子父亲的儿子更可能比父亲高;而高个子父亲的儿子更可能比父亲矮。受表哥查尔斯·达尔文的影响,高尔顿将这种现象称为“回归效应”,即大自然将人类身高的分布约束在相对稳定而不产生两极分化的整体水平,并给出了历史上第一个线性回归的表达式:y = 0.516x + 33.73,式中的 y 和 x 分别代表以英寸为单位的子代和父代的身高。
高尔顿的思想在今天的机器学习中依然保持着旺盛的生命力。假定一个实例可以用列向量 x=(x1;x2;⋯,xn) 表示,每个 xi 代表了实例在第 i 个属性上的取值,线性回归的作用就是习得一组参数 wi,i=0,1,⋯,n,使预测输出可以表示为以这组参数为权重的实例属性的线性组合。如果引入常量 x0=1,线性回归试图学习的模型就是
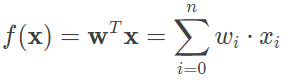
当实例只有一个属性时,输入和输出之间的关系就是二维平面上的一条直线;当实例的属性数目较多时,线性回归得到的就是 n+1 维空间上的一个超平面,对应一个维度等于 n 的线性子空间。在训练集上确定系数 wi 时,预测输出 f(x) 和真实输出 y 之间的误差是关注的核心指标。在线性回归中,这一误差是以均方误差来定义的。当线性回归的模型为二维平面上的直线时,均方误差就是预测输出和真实输出之间的欧几里得距离,也就是两点间向量的 L2 范数。而以使均方误差取得最小值为目标的模型求解方法就是最小二乘法,其表达式可以写成
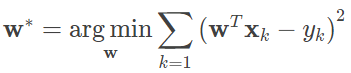
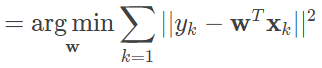
式中每个 xk 代表训练集中的一个样本。在单变量线性回归任务中,最小二乘法的作用就是找到一条直线,使所有样本到直线的欧式距离之和最小。说到这里,问题就来了:凭什么使均方误差最小化的参数就是和训练样本匹配的最优模型呢?这个问题可以从概率论的角度阐释。线性回归得到的是统计意义上的拟合结果,在单变量的情形下,可能每一个样本点都没有落在求得的直线上。
对这个现象的一种解释是回归结果可以完美匹配理想样本点的分布,但训练中使用的真实样本点是理想样本点和噪声叠加的结果,因而与回归模型之间产生了偏差,而每个样本点上噪声的取值就等于 yk−f(xk)。假定影响样本点的噪声满足参数为 (0,σ2) 的正态分布(还记得正态分布的概率密度公式吗?),这意味着噪声等于 0 的概率密度最大,幅度(无论正负)越大的噪声出现的概率越小。在这种情形下,对参数 w 的推导就可以用最大似然的方式进行,即在已知样本数据及其分布的条件下,找到使样本数据以最大概率出现的假设。
单个样本 xk 出现的概率实际上就是噪声等于 yk−f(xk) 的概率,而相互独立的所有样本同时出现的概率则是每个样本出现概率的乘积,其表达式可以写成
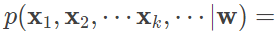
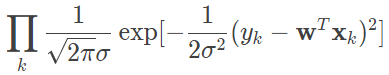
而最大似然估计的任务就是让以上表达式的取值最大化。出于计算简便的考虑,上面的乘积式可以通过取对数的方式转化成求和式,且取对数的操作并不会影响其单调性。经过一番运算后,上式的最大化就可以等效为 k∑(yk−wTxk)2 的最小化。因此,对于单变量线性回归而言,在误差函数服从正态分布的情况下,从几何意义出发的最小二乘法与从概率意义出发的最大似然估计是等价的。
确定了最小二乘法的最优性,接下来的问题就是如何求解均方误差的最小值。在单变量线性回归中,其回归方程可以写成 y=w1x+w0。根据最优化理论,将这一表达式代入均方误差的表达式中,并分别对 w1 和 w0 求偏导数,令两个偏导数均等于 0 的取值就是线性回归的最优解,其解析式可以写成
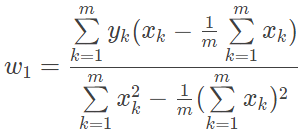
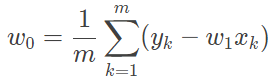
单变量线性回归只是一种最简单的特例。子代的身高并非仅仅由父母的遗传基因决定,营养条件、生活环境等因素都会产生影响。当样本的描述涉及多个属性时,这类问题就被称为多元线性回归。多元线性回归中的参数 w 也可以用最小二乘法进行估计,其最优解同样用偏导数确定,但参与运算的元素从向量变成了矩阵。在理想的情况下,多元线性回归的最优参数为
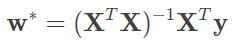
式中的 X 是由所有样本 x=(x0;x1;x2;⋯,xn) 的转置共同构成的矩阵。但这一表达式只在矩阵 (XTX) 的逆矩阵存在时成立。在大量复杂的实际任务中,每个样本中属性的数目甚至会超过训练集中的样本总数,此时求出的最优解 w∗ 就不是唯一的,解的选择将依赖于学习算法的归纳偏好。
但不论采用怎样的选取标准,存在多个最优解都是无法改变的事实,这也意味着过拟合的产生。更重要的是,在过拟合的情形下,微小扰动给训练数据带来的毫厘之差可能会导致训练出的模型谬以千里,模型的稳定性也就无法保证。要解决过拟合问题,常见的做法是正则化,即添加额外的惩罚项。在线性回归中,正则化的方式根据其使用惩罚项的不同可以分为两种,分别是“岭回归”和“LASSO 回归”。
在机器学习中,岭回归方法又被称为“参数衰减”,于 20 世纪 40 年代由前苏联学者安德烈·季霍诺夫提出。当然,彼时机器学习尚未诞生,季霍诺夫提出这一方法的主要目的是解决矩阵求逆的稳定性问题,其思想后来被应用到正则化中,形成了今天的岭回归。岭回归实现正则化的方式是在原始均方误差项的基础上添加一个待求解参数的二范数项,即最小化的对象变为 ∣∣yk−wTxk∣∣2+∣∣Γw∣∣2,其中的 Γ 被称为季霍诺夫矩阵,通常可以简化为一个常数。
从最优化的角度看,二范数惩罚项的作用在于优先选择范数较小的 w,这相当于在最小均方误差之外额外添加了一重关于最优解特性的约束条件,将最优解限制在高维空间内的一个球里。岭回归的作用相当于在原始最小二乘的结果上做了缩放,虽然最优解中每个参数的贡献被削弱了,但参数的数目并没有变少。LASSO 回归的全称是“最小绝对缩减和选择算子”(Least Absolute Shrinkage and Selection Operator),由加拿大学者罗伯特·提布什拉尼于 1996 年提出。与岭回归不同的是,LASSO 回归选择了待求解参数的一范数项作为惩罚项,即最小化的对象变为 ∣∣yk−wTxk∣∣2+λ∣∣w∣∣1,其中的 λ 是一个常数。
与岭回归相比,LASSO 回归的特点在于稀疏性的引入。它降低了最优解 w 的维度,也就是将一部分参数的贡献削弱为 0,这就使得 w 中元素的数目大大小于原始特征的数目。这或多或少可以看作奥卡姆剃刀原理的一种实现:当主要矛盾和次要矛盾同时存在时,优先考虑的必然是主要矛盾。虽然饮食、环境、运动等因素都会影响身高的变化,但决定性因素显然只存在在染色体上。值得一提的是,引入稀疏性是简化复杂问题的一种常用方法,在数据压缩、信号处理等其他领域中亦有广泛应用。
从概率的角度来看,最小二乘法的解析解可以利用正态分布以及最大似然估计求得,这在前文已有说明。岭回归和 LASSO 回归也可以从概率的视角进行阐释:岭回归是在 wi 满足正态先验分布的条件下,用最大后验概率进行估计得到的结果;LASSO 回归是在 wi 满足拉普拉斯先验分布的条件下,用最大后验概率进行估计得到的结果。但无论岭回归还是 LASSO 回归,其作用都是通过惩罚项的引入抑制过拟合现象,以训练误差的上升为代价,换取测试误差的下降。将以上两种方法的思想结合可以得到新的优化方法。
机器学习中的线性回归算法解决的是从连续取值的输入映射为连续取值的输出的回归问题。用于解决分类问题算法,即将连续取值的输入映射为离散取值的输出,算法的名字叫作“朴素贝叶斯方法”。解决分类问题的依据是数据的属性。朴素贝叶斯分类器假定样本的不同属性满足条件独立性假设,并在此基础上应用贝叶斯定理执行分类任务。其基本思想在于分析待分类样本出现在每个输出类别中的后验概率,并以取得最大后验概率的类别作为分类的输出。
假设训练数据的属性由 n 维随机向量 x 表示,其分类结果用随机变量 y 表示,那么 x 和 y 的统计规律就可以用联合概率分布 P(X,Y) 描述,每一个具体的样本 (xi,yi) 都可以通过 P(X,Y) 独立同分布地产生。朴素贝叶斯分类器的出发点就是这个联合概率分布,根据条件概率的性质可以得到
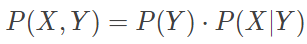
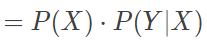
在上式中,P(Y) 代表着每个类别出现的概率,也就是类先验概率;P(X|Y) 代表着在给定的类别下不同属性出现的概率,也就是类似然概率。先验概率容易根据训练数据计算出来,只需要统计不同类别样本的数目即可。而似然概率受属性取值数目的影响,其估计较为困难。
如果每个样本包含 100 个属性,每个属性的取值都可能有 100 种,那么对分类的每个结果,要计算的条件概率数目就是 1002=10000。在这么多参数的情况下,对似然概率的精确估计就需要庞大的数据量。要解决似然概率难以估计的问题,就需要“条件独立性假设”登台亮相。条件独立性假设保证了所有属性相互独立,互不影响,每个属性独立地对分类结果发生作用。这样类条件概率就变成了属性条件概率的乘积,在数学公式上可以体现为
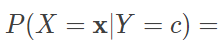
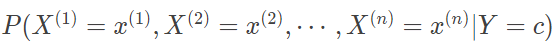
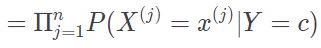
这正是朴素贝叶斯方法的“朴素”之处,通过必要的假设来简化计算,并回归问题的本质。条件独立性假设对似然概率的估计无疑是个天大的好消息。没有这一假设时,每个样本的分类结果 y 只能刻画其所有属性 x1,x2,⋯,xn 形成的整体,只有具有相同 x1,x2,⋯,xn 的样本才能放在一起进行评价。当属性数目较多且数据量较少时,要让 n 个属性同时取到相同的特征就需要些运气了。
有了条件独立性假设后,分类结果 y 就相当于实现了 n 重复用。每一个样本既可以用于刻画 x1,又可以用于刻画 xn,这无形中将训练样本的数量扩大为原来的 n 倍,分析属性的每个取值对分类结果的影响时,也有更多数据作为支撑。但需要说明的是,属性的条件独立性假设是个相当强的假设。
一个例子是银行在发放房贷时,需要对贷款申请人的情况进行调研,以确定是否发放贷款。本质上这就是个分类问题,分类的结果是“是”与“否”。分类时则需要考虑申请人的年龄、工作岗位、婚姻状况、收入水平、负债情况等因素。这些因素显然不是相互独立的。中年人的收入通常会高于青年人的收入,已婚者的负债水平通常也会高于未婚者的负债水平。因而在实际应用中,属性条件独立性假设会导致数据的过度简化,因而会给分类性能带来些许影响。但它带来的数学上的便利却能极大简化分类问题的计算复杂度,性能上的部分折中也就并非不可接受。
有了训练数据集,先验概率 P(Y) 和似然概率 P(X|Y) 就可以视为已知条件,用来求解后验概率 P(Y|X)。对于给定的输入 x,朴素贝叶斯分类器利用贝叶斯定理求解后验概率,并将后验概率最大的类作为输出。由于在所有后验概率的求解中,边界概率 P(X) 都是相同的,因而其影响可以忽略。将属性条件独立性假设应用于后验概率求解中,就可以得到朴素贝叶斯分类器的数学表达式

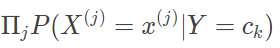
应用朴素贝叶斯分类器处理连续型属性数据时,通常假定属性数据满足正态分布,再根据每个类别下的训练数据计算出正态分布的均值和方差。从模型最优化的角度观察,朴素贝叶斯分类器是平均意义上预测能力最优的模型,也就是使期望风险最小化。期望风险是风险函数的数学期望,度量的是平均意义下模型预测的误差特性,可以视为单次预测误差在联合概率分布 P(X, Y) 上的数学期望。朴素贝叶斯分类器通过将实例分配到后验概率最大的类中,也就同时让 1 - P(Y|X) 取得最小值。在以分类错误的实例数作为误差时,期望风险就等于 1 - P(Y|X)。这样一来,后验概率最大化就等效于期望风险最小化。
受训练数据集规模的限制,某些属性的取值在训练集中可能从未与某个类同时出现,这就可能导致属性条件概率为 0,此时直接使用朴素贝叶斯分类就会导致错误的结论。还是以贷款申请为例,如果在训练集中没有样本同时具有“年龄大于 60”的属性和“发放贷款”的标签,那么当一个退休人员申请贷款时,即使他是坐拥百亿身家的李嘉诚,朴素贝叶斯分类器也会因为后验概率等于零而将他无情拒绝。
因为训练集样本的不充分导致分类错误,显然不是理想的结果。为了避免属性携带的信息被训练集中未曾出现过的属性值所干扰,在计算属性条件概率时需要添加一个称为“拉普拉斯平滑”的步骤。所谓拉普拉斯平滑就是在计算类先验概率和属性条件概率时,在分子上添加一个较小的修正量,在分母上则添加这个修正量与分类数目的乘积。这就可以保证在满足概率基本性质的条件下,避免了零概率对分类结果的影响。当训练集的数据量较大时,修正量对先验概率的影响也就可以忽略不计了。
事实上,朴素贝叶斯是一种非常高效的方法。当以分类的正确与否作为误差指标时,只要朴素贝叶斯分类器能够把最大的后验概率找到,就意味着它能实现正确的分类。至于找到的最大后验概率的估计值是否精确,反而没那么重要了。如果一个实例在两个类别上的后验概率分别是 0.9 和 0.1,朴素贝叶斯分类器估计出的后验概率就可能是 0.6 和 0.4。虽然数值的精度相差较大,但大小的相对关系并未改变。依据这个粗糙估计的后验概率进行分类,得到的依然是正确的结果。上面的说法固然言之成理,却不能解释另外一个疑问。虽然属性条件独立性看起来像是空中楼阁,却给朴素贝叶斯分类器带来了实实在在的优良性能,这其中的奥秘何在?为什么在基础假设几乎永远不成立的情况下,朴素贝叶斯依然能够在绝大部分分类任务中体现出优良性能呢?
一种可能的解释是:在给定的训练数据集上,两个属性之间可能具有相关性,但这种相关性在每个类别上都以同样的程度体现。 这种情况显然违背了条件独立性假设,却不会破坏朴素贝叶斯分类器的最优性。即使相关性在不同类别上的分布不是均匀的也没关系,只看两个单独的属性,它们之间可能存在强烈的依赖关系,会影响分类的结果。但当所有属性之间的依赖关系一起发挥作用时,它们就可能相互抵消,不再影响分类。
简而言之,决定性的因素是所有属性之间的依赖关系的组合。影响朴素贝叶斯的分类的是所有属性之间的依赖关系在不同类别上的分布,而不仅仅是依赖关系本身。可即便如此,属性条件独立性假设依然会影响分类性能。为了放宽这一假设,研究人员又提出了“半朴素贝叶斯分类器”的学习方法。半朴素贝叶斯分类器考虑了部分属性之间的依赖关系,既保留了属性之间较强的相关性,又不需要完全计算复杂的联合概率分布。常用的方法是建立独依赖关系:假设每个属性除了类别之外,最多只依赖一个其他属性。由此,根据属性间依赖关系确定方式的不同,便衍生出了多种独依赖分类器。
朴素贝叶斯分类器的应用场景非常广泛。它可以根据关键词执行对一封邮件是否是垃圾邮件的二元分类,也可以用来判断社交网络上的账号到底是活跃用户还是僵尸粉。在信息检索领域,这种分类方法尤为实用。总结起来,以朴素贝叶斯分类器为代表的贝叶斯分类方法的策略是:根据训练数据计算后验概率,基于后验概率选择最佳决策。
朴素贝叶斯分类算法解决的是将连续取值的输入映射为离散取值的输出的分类问题。朴素贝叶斯分类器是一类生成模型,通过构造联合概率分布 P(X,Y) 实现分类。如果换一种思路,转而用判别模型解决分类问题的话,得到的算法就是“逻辑回归”。虽然顶着“回归”的名号,但逻辑回归解决的却是实打实的分类问题。之所以取了这个名字,原因在于它来源于对线性回归算法的改进。通过引入单调可微函数 g(⋅),线性回归模型就可以推广为 y=g−1(wTx),进而将线性回归模型的连续预测值与分类任务的离散标记联系起来。当 g(⋅) 取成对数函数的形式时,线性回归就演变为了逻辑回归。
在最简单的二分类问题中,分类的标记可以抽象为 0 和 1,因而线性回归中的实值输出需要映射为二进制的结果。逻辑回归中,实现这一映射是对数几率函数,也叫 Sigmoid 函数
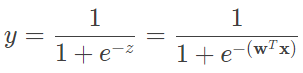
之所以选择对数几率函数,是因为它具备良好的特性。首先,对数几率函数能够将线性回归从负无穷到正无穷的输出范围压缩到 (0, 1) 之间,无疑更加符合对二分类任务的直观感觉。其次,当线性回归的结果 z=0 时,逻辑回归的结果 y=0.5,这可以视为一个分界点:当 z>0 时,y>0.5,此时逻辑回归的结果就可以判为正例;当 z<0 时,y<0.5,逻辑回归的结果就可以判为反例。显然,对数几率函数能够在线性回归和逻辑回归之间提供更好的可解释性。这种可解释性可以从数学的角度进一步诠释。
如果将对数几率函数的结果 y 视为样本 x 作为正例的可能性,则 1−y 就是其作为反例的可能性,两者的比值 0<y/(1−y)<+∞ 称为几率,体现的是样本作为正例的相对可能性。如果对几率函数取对数,并将前文中的公式代入,可以得到
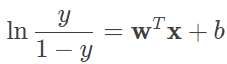
由此可见,当利用逻辑回归模型解决分类任务时,线性回归的结果正是以对数几率的形式出现的。归根结底,逻辑回归模型由条件概率分布表示
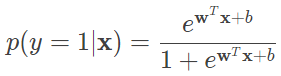

对于给定的实例,逻辑回归模型比较两个条件概率值的大小,并将实例划分到概率较大的分类之中。学习时,逻辑回归模型在给定的训练数据集上应用最大似然估计法确定模型的参数。对给定的数据集 (xi,yi),逻辑回归使每个样本属于其真实标记的概率最大化,以此为依据确定 w 的最优值。由于每个样本的输出 yi 都满足两点分布,且不同的样本之间相互独立,因而似然函数可以表示为
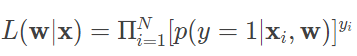
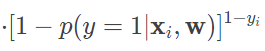
利用对数操作将乘积转化为求和,就可以得到对数似然函数
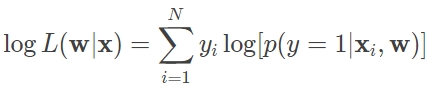
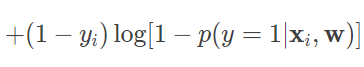
由于单个样本的标记 yi 只能取得 0 或 1,因而上式中的两项中只有一个有非零的取值。将每个条件概率的对数几率函数形式代入上式,经过化简可以得到
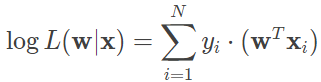

寻找以上函数的最大值就是以对数似然函数为目标函数的最优化问题,通常通过“梯度下降法”或拟“牛顿法”求解。当训练数据集是从所有数据中均匀抽取且数量较大时,以上结果还有一种信息论角度的阐释方式:对数似然函数的最大化可以等效为待求模型与最大熵模型之间 KL 散度的最小化。这意味着最优的估计对参数做出的额外假设是最少的,这无疑与最大熵原理不谋而合。从数学角度看,线性回归和逻辑回归之间的渊源来源于非线性的对数似然函数;而从特征空间的角度看,两者的区别则在于数据判定边界的变化。判定边界可以类比为棋盘上的楚河汉界,边界两侧分别对应不同类型的数据。
以最简单的二维平面直角坐标系为例。受模型形式的限制,利用线性回归只能得到直线形式的判定边界;逻辑回归则在线性回归的基础上,通过对数似然函数的引入使判定边界的形状不再受限于直线,而是推广为更加复杂的曲线形式,更加精细的分类也就不在话下。逻辑回归与线性回归的关系称得上系出同门,与朴素贝叶斯分类的关系则是殊途同归。两者虽然都可以利用条件概率 P(Y∣X) 完成分类任务,实现的路径却截然不同。
朴素贝叶斯分类器是生成模型的代表,其思想是先由训练数据集估计出输入和输出的联合概率分布,再根据联合概率分布来生成符合条件的输出,P(Y∣X) 以后验概率的形式出现。逻辑回归模型则是判别模型的代表,其思想是先由训练数据集估计出输入和输出的条件概率分布,再根据条件概率分布来判定对于给定的输入应该选择哪种输出,P(Y∣X) 以似然概率的形式出现。
即便原理不同,逻辑回归与朴素贝叶斯分类器在特定的条件下依然可以等效。用朴素贝叶斯分类器处理二分类任务时,假设对每个 xi,属性条件概率 p(xi∣Y=yk) 都满足正态分布,且正态分布的标准差与输出标记 Y 无关,那么根据贝叶斯定理,后验概率就可以写成
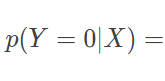
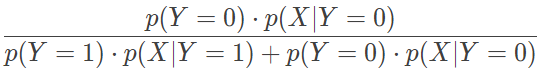
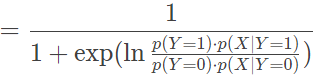
根据朴素贝叶斯方法的假设,类条件概率可以表示为属性条件概率的乘积,因而令 p(Y=0)=p0 并将满足正态分布的属性条件概率 p(xi∣Y=yk) 代入以上表达式中,经过一番计算就可以得到
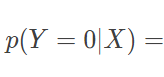
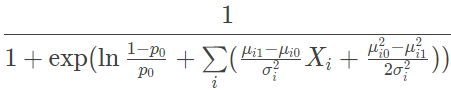
不难看出,上式的形式和逻辑回归中条件概率 p(y=0∣x) 的形式是完全一致的,这表明朴素贝叶斯方法和逻辑回归模型学习到的是同一个模型。实际上,在 p(x∣Y) 的分布属于指数分布族这个更一般的假设下,类似的结论都是成立的。
说完了联系,再来看看区别。两者的区别在于当朴素贝叶斯分类的模型假设不成立时,逻辑回归和朴素贝叶斯方法通常会学习到不同的结果。当训练样本数接近无穷大时,逻辑回归的渐近分类准确率要优于朴素贝叶斯方法。而且逻辑回归并不完全依赖于属性之间相互独立的假设,即使给定违反这一假设的数据,逻辑回归的条件似然最大化算法也会调整其参数以实现最大化的数据拟合。相比之下,逻辑回归的偏差更小,但方差更大。
除此之外,两者的区别还在于收敛速度的不同。逻辑回归中参数估计的收敛速度要慢于朴素贝叶斯方法。当训练数据集的容量较大时,逻辑回归的性能优于朴素贝叶斯方法;但在训练数据稀缺时,两者的表现就会发生反转。二分类任务只是特例,更通用的情形是多分类的问题,例如手写数字的识别。要让逻辑回归处理多分类问题,就要做出一些改进。一种改进方式是通过多次二分类实现多个类别的标记。这等效为直接将逻辑回归应用在每个类别之上,对每个类别都建立一个二分类器。如果输出的类别标记数目为 m,就可以得到 m 个针对不同标记的二分类逻辑回归模型,而对一个实例的分类结果就是这 m 个分类函数中输出值最大的那个。在这种方式中,对一个实例执行分类需要多次使用逻辑回归算法,其效率显然比较低下。
另一种多分类的方式通过直接修改逻辑回归输出的似然概率,使之适应多分类问题,得到的模型就是 Softmax 回归。Softmax 回归给出的是实例在每一种分类结果下出现的概率
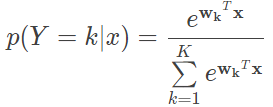
式中的 wk 代表和类别 k 相关的权重参数。Softmax 回归模型的训练与逻辑回归模型类似,都可以转化为通过梯度下降法或者拟牛顿法解决最优化问题。虽然都能实现多分类的任务,但两种方式的适用范围略有区别。当分类问题的所有类别之间明显互斥,即输出结果只能属于一个类别时,Softmax 分类器是更加高效的选择;当所有类别之间不存在互斥关系,可能有交叉的情况出现时,多个二分类逻辑回归模型就能够得到多个类别的标记。
决策树算法是解决分类问题的另一种方法。与基于概率推断的朴素贝叶斯分类器和逻辑回归模型不同,决策树算法采用树形结构,使用层层推理来实现最终的分类。与贝叶斯分类器相比,决策树的优势在于构造过程无需使用任何先验条件,因而适用于探索式的知识发现。决策树的分类方法更接近人类的判断机制,这可以通过买房的实例说明。
面对眼花缭乱的房源,普通人优先考虑的都是每平方米的价格因素,价格不贵就买,价格贵了就不买。在价格合适的前提下,面积就是下一个待确定的问题,面积不小就买,面积小了就不买。如果面积合适,位置也是不容忽视的因素,单身业主会考虑房源离工作地点的远近,离单位近就买,离单位远就不买;为人父母的则要斟酌是不是学区房,是学区房就买,不是学区房就不买。如果位置同样称心,就可以再根据交通是否便捷、物业是否良好、价格是否有优惠等条件进一步筛选,确定最后的购买对象。前面的例子模拟了一套购房策略。在这套策略中,业主对每个可选房源都要做出“买”与“不买”的决策结果,而“每平米价格”、“房屋面积”、“学区房”等因素共同构成了决策的判断条件,在每个判断条件下的选择表示的是不同情况下的决策路径,而每个“买”或是“不买”的决定背后都包含一系列完整的决策过程。决策树就是将以上过程形式化、并引入量化指标后形成的分类算法。
决策树是一个包含根节点、内部节点和叶节点的树结构,其根节点包含样本全集,内部节点对应特征属性测试,叶节点则代表决策结果。从根节点到每个叶节点的每条路径都对应着一个从数据到决策的判定流程。使用决策树进行决策的过程就是从根节点开始,测试待分类项的特征属性,并按照其值选择输出的内部节点。当选择过程持续到到达某个叶节点时,就将该叶节点存放的类别作为决策结果。由于决策树是基于特征对实例进行分类的,因而其学习的本质是从训练数据集中归纳出一组用于分类的“如果...... 那么......”规则。在学习的过程中,这组规则集合既要在训练数据上有较高的符合度,也要具备良好的泛化能力。决策树模型的学习过程包括三个步骤:特征选择、决策树生成和决策树剪枝。
特征选择决定了使用哪些特征来划分特征空间。在训练数据集中,每个样本的属性可能有很多个,在分类结果中起到的作用也有大有小。因而特征选择的作用在于筛选出与分类结果相关性较高,也就是分类能力较强的特征。理想的特征选择是在每次划分之后,分支节点所包含的样本都尽可能属于同一个类别。在特征选择中通常使用的准则是信息增益。机器学习中的信息增益就是通信理论中的互信息,是信息论的核心概念之一。信息增益描述的是在已知特征后对数据分类不确定性的减少程度,因而特征的信息增益越大,得到的分类结果的不确定度越低,特征也就具有越强的分类能力。根据信息增益准则选择特征的过程,就是自顶向下进行划分,在每次划分时计算每个特征的信息增益并选取最大值的过程。信息增益的计算涉及信源熵和条件熵的公式,这在前面的专栏内容中有所涉及,在此就不重复了。
信息增益的作用可以用下面的实例来定性说明。在银行发放贷款时,会根据申请人的特征决定是否发放。假设在贷款申请的训练数据中,每个样本都包含年龄、是否有工作、是否有房产、信贷情况等特征,并根据这些特征确定是否同意贷款。一种极端的情形是申请人是否有房产的属性取值和是否同意贷款的分类结果完全吻合,即在训练数据中,每个有房的申请人都对应同意贷款,而每个没房的申请人都对应不同意贷款。这种情况下,“是否有房产”这个特征就具有最大的信息增益,它完全消除了分类结果的不确定性。在处理测试实例时,只要根据这个特征就可以确定分类结果,甚至无需考虑其他特征的取值。
相比之下,另一种极端的情形是申请人的年龄和是否同意贷款的分类结果可能完全无关,即在训练数据中,青年 / 中年 / 老年每个年龄段内,同意贷款与不同意贷款的样本数目都大致相等。这相当于分类结果在年龄特征每个取值上都是随机分布的,两者之间没有任何规律可言。这种特征的信息增益很小,也不具备分类能力。一般来说,抛弃这样的特征对决策树学习精度的影响不大。在最早提出的决策树算法——ID3 算法中,决策树的生成就利用信息增益准则选择特征。ID3 算法构建决策树的具体方法是从根节点出发,对节点计算所有特征的信息增益,选择信息增益最大的特征作为节点特征,根据该特征的不同取值建立子节点;对每个子节点都递归调用以上算法生成新的子节点,直到信息增益都很小或没有特征可以选择为止。
ID3 算法使用的是信息增益的绝对取值,而信息增益的运算特性决定了当属性的可取值数目较多时,其信息增益的绝对值将大于取值较少的属性。这样一来,如果在决策树的初始阶段就进行过于精细的分类,其泛化能力就会受到影响,无法对真实的实例做出有效预测。为了避免信息增益准则对多值属性的偏好,ID3 算法的提出者在其基础上提出了改进版,也就是 C4.5 算法。C4.5 算法不是直接使用信息增益,而是引入“信息增益比”指标作为最优划分属性选择的依据。信息增益比等于使用属性的特征熵归一化后的信息增益,而每个属性的特征熵等于按属性取值计算出的信息熵。在特征选择时,C4.5 算法先从候选特征中找出信息增益高于平均水平的特征,再从中选择增益率最高的作为节点特征,这就保证了对多值属性和少值属性一视同仁。在决策树的生成上,C4.5 算法与 ID3 算法类似。
无论是 ID3 算法还是 C4.5 算法,都是基于信息论中熵模型的指标实现特征选择,因而涉及大量的对数计算。另一种主要的决策树算法 CART 算法则用基尼系数取代了熵模型。CART 算法的全称是分类与回归树(Classification and Regression Tree),既可以用于分类也可以用于回归。假设数据中共有 K 个类别,第 k 个类别的概率为 pk,则基尼系数等于![]()
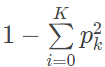
基尼系数在与熵模型高度近似的前提下,避免了对数运算的使用,使得 CART 分类树具有较高的执行效率。为了进一步简化分类模型,CART 分类树算法每次只对某个特征的值进行二分而非多分,最终生成的就是二叉树模型。因而在计算基尼系数时,需要对每个特征找到使基尼系数最小的最优切分点,在树生成时根据最优特征和最优切分点生成两个子节点,将训练数据集按照特征分配到子节点中去。如果在某个特征 A 上有 A1、A2 和 A3 三种类别,CART 分类树在进行二分时就会考虑{A1}/{A2,A3}、{A2}/{A1,A3}、{A3}/{A1,A2}这三种分类方法,从中找到基尼系数最小的组合。
同其他机器学习算法一样,决策树也难以克服过拟合的问题,“剪枝”是决策树对抗过拟合的主要手段。园丁给树苗剪枝是为了让树形完好,决策树剪枝则是通过主动去掉分支以降低过拟合的风险,提升模型的泛化性能。那么如何判定泛化性能的提升呢?其方法是定义决策树整体的损失函数并使之极小化,这等价于使用正则化的最大似然估计进行模型选择。另一种更简单的方法是在训练数据集中取出一部分用于模型验证,根据验证集分类精度的变化决定是否进行剪枝。决策树的剪枝策略可以分为预剪枝和后剪枝。
预剪枝是指在决策树的生成过程中,在划分前就对每个节点进行估计,如果当前节点的划分不能带来泛化性能的提升,就直接将当前节点标记为叶节点。预剪枝的好处在于禁止欠佳节点的展开,在降低过拟合风险的同时显著减少了决策树的时间开销。但它也会导致“误伤”的后果,某些分支虽然当前看起来没用,在其基础上的后续划分却可能让泛化性能显著提升,预剪枝策略将这些深藏不露的节点移除,无疑会矫枉过正,带来欠拟合的风险。
相比之下,后剪枝策略是先从训练集生成一棵完整的决策树,计算其在验证集上的分类精度,再在完整决策树的基础上剪枝,通过比较剪枝前和剪枝后的分类精度决定分支是否保留。和预剪枝相比,后剪枝策略通常可以保留更多的分支,其欠拟合的风险较小。但由于需要逐一考察所有内部节点,因而其训练开销较大。以上的决策树算法虽然结构上简单直观,逻辑上容易解释,但一个重要缺点是“一言堂”,即只依据一个最优特征执行分类决策。在实际问题中,分类结果通常会受到多个因素的影响,因而需要对不同特征综合考虑。依赖多个特征进行分类决策的就是多变量决策树。在特征空间上,单变量决策树得到的分类边界是与坐标轴平行的分段,多变量决策树的分类边界则是斜线的形式。
1963 年,在前苏联莫斯科控制科学学院攻读统计学博士学位的弗拉基米尔·瓦普尼克和他的同事阿列克谢·切尔沃宁基斯共同提出了支持向量机算法,随后几年两人又在此基础上进一步完善了统计学习理论。可受当时国际环境的影响,这些以俄文发表的成果并没有得到西方学术界的重视。直到 1990 年,瓦普尼克随着移民潮到达美国,统计学习理论才得到了它应有的重视,并在二十世纪末大放异彩。瓦普尼克本人也于 2014 年加入 Facebook 的人工智能实验室,并获得了包括罗森布拉特奖和冯诺伊曼奖章等诸多个人荣誉。具体说来,支持向量机是一种二分类算法,通过在高维空间中构造超平面实现对样本的分类。最简单的情形是训练数据线性可分的情况,此时的支持向量机就被弱化为线性可分支持向量机,这可以视为广义支持向量机的一种特例。
线性可分的数据集可以简化为二维平面上的点集。在平面直角坐标系中,如果有若干个点全部位于 x 轴上方,另外若干个点全部位于 x 轴下方,这两个点集就共同构成了一个线性可分的训练数据集,而 x 轴就是将它们区分开来的一维超平面,也就是直线。如果在上面的例子上做进一步的假设,假定 x 轴上方的点全部位于直线 y=1 上及其上方,x 轴下方的点全部位于直线 y=−2 上及其下方。如此一来,任何平行于 x 轴且在 (-2, 1) 之间的直线都可以将这个训练集分开。那么问题来了:在这么多划分超平面中,哪一个是最好的呢?
直观看来,最好的分界线应该是直线 y=−0.5,因为这条分界线正好位于两个边界的中间,与两个类别的间隔可以同时达到最大。当训练集中的数据因噪声干扰而移动时,这个最优划分超平面的划分精确度所受的影响最小,因而具有最强的泛化能力。在高维的特征空间上,划分超平面可以用简单的线性方程描述
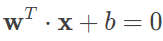
式中的 n 维向量 w 为法向量,决定了超平面的方向;b 为截距,决定了超平面和高维空间中原点的距离。划分超平面将特征空间分为两个部分。位于法向量所指向一侧的数据被划分为正类,其分类标记 y=+1;位于另一侧的数据被划分为负类,其分类标记 y=−1。线性可分支持向量机就是在给定训练数据集的条件下,根据间隔最大化学习最优的划分超平面的过程。给定超平面后,特征空间中的样本点 xi 到超平面的距离可以表示为
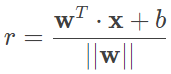
显然,这个距离是个归一化的距离,因而被称为几何间隔。结合前文的描述,通过合理设置参数 w 和 b,可以使每个样本点到最优划分超平面的距离都不小于 -1,即满足以下关系
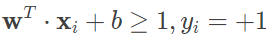
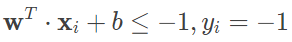
需要注意的是,式中的距离是非归一化的距离,被称为函数间隔。函数间隔和几何间隔的区别就在于未归一化和归一化的区别。在特征空间中,距离划分超平面最近的样本点能让上式取得等号,这些样本被称为“支持向量”,两个异类支持向量到超平面的距离之和为 2/∣∣w∣∣。因而对于线性可分支持向量机来说,其任务就是在满足上面不等式的条件下,寻找 2/∣∣w∣∣ 的最大值。由于最大化 ∣∣w∣∣−1 等效于最小化 ∣∣w∣∣2,因而上述问题可以改写为求解 21∣∣w∣∣2 的最小值。
线性可分支持向量机是使硬间隔最大化的算法。在实际问题中,训练数据集中通常会出现噪声或异常点,导致其线性不可分。要解决这个问题就需要将学习算法一般化,得到的就是线性支持向量机(去掉了“可分”条件)。线性支持向量机的通用性体现在将原始的硬间隔最大化策略转变为软间隔最大化。在线性不可分的训练集中,导致不可分的只是少量异常点,只要把这些异常点去掉,余下的大部分样本点依然满足线性可分的条件。
从数学上看,线性不可分意味着某些样本点距离划分超平面的函数间隔不满足不小于 1 的约束条件,因而需要对每个样本点引入大于零的松弛变量 ξ≥0,使得函数间隔和松弛变量的和不小于 1。这样一来,软间隔最大化下的约束条件就变成
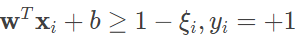
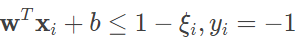
相应地,最优化问题中的目标函数就演变为
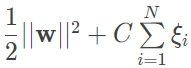
其中 C>0 被称为惩罚参数,表示对误分类的惩罚力度。这个最小化目标函数既使函数间隔尽量大,也兼顾了误分类点的个数。与要求所有样本都划分正确的硬间隔相比,软间隔允许某些样本不满足硬间隔的约束,但会限制这类特例的数目。前文中涉及的分类问题都假定两类数据点可以用原始特征空间上的超平面区分开来,这类问题就是线性问题;如果原始空间中不存在能够正确划分的超平面,问题就演变成了非线性问题。在二维平面直角坐标系中,如果按照与原点之间的距离对数据点进行分类的话,分类的模型就不再是一条直线,而是一个圆,也就是超曲面。这个问题就是个非线性问题,与距离的平方形式相呼应。
不论是线性可分支持向量机还是线性支持向量机,都只能处理线性问题,对于非线性问题则无能为力。可如果能将样本从原始空间映射到更高维度的特征空间之上,在新的特征空间上样本就可能是线性可分的。如果样本的属性数有限,那么一定存在一个高维特征空间使样本可分。将原始低维空间上的非线性问题转化为新的高维空间上的线性问题,这就是核技巧的基本思想。核技巧的例子可以用中国象棋来解释。开战之前,红黑两军各自陈兵,不越雷池一步,只需楚河汉界便可让不同的棋子泾渭分明。可随着车辚辚马萧萧激战渐酣,红黑棋子捉对厮杀,难分敌我,想要再造一条楚河汉界将混在一起的两军区分开已无可能。
好在我们还有高维空间。不妨把两军之争想象成一场围城大战,红帅率兵于高墙坚守,黑将携卒在低谷强攻。如此一来,不管棋盘上的棋子如何犬牙交错,只要能够在脑海中构造出一个立体城池,便可以根据位置的高低将红黑区分开来。这,就是棋盘上的核技巧。当核技巧应用到支持向量机中时,原始空间与新空间之间的转化是通过非线性变换实现的。假设原始空间是低维欧几里得空间X,新空间为高维希尔伯特空间H,则从 X 到 H 的映射可以用函数 ϕ(x):X→H 表示。核函数可以表示成映射函数内积的形式,即
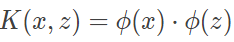
核函数有两个特点。第一,其计算过程是在低维空间上完成的,因而避免了高维空间(可能是无穷维空间)中复杂的计算;第二,对于给定的核函数,高维空间 H 和映射函数 ϕ 的取法并不唯一。一方面,高维空间的取法可以不同;另一方面,即使在同一个空间上,映射函数也可以有所区别。核函数的使用涉及一些复杂的数学问题,其结论是一般的核函数都是正定核函数。正定核函数的充要条件是由函数中任意数据的集合形成的核矩阵都是半正定的,这意味着任何一个核函数都隐式定义了一个成为“再生核希尔伯特空间”的特征空间,其中的数学推导在此不做赘述。在支持向量机的应用中,核函数的选择是一个核心问题。不好的核函数会将样本映射到不合适的特征空间,从而导致分类性能不佳。常用的核函数包括以下几种:
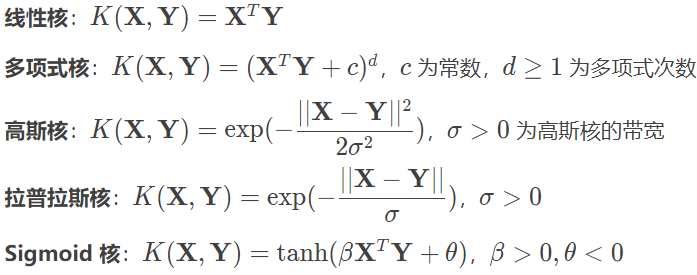
核函数可以将线性支持向量机扩展为非线性支持向量机。非线性支持向量机的约束条件比较复杂,受篇幅所限,在此没有给出,你可以从相关书籍中查阅。非线性支持向量机是最普适的情形,前文中的两种情况都可以视为非线性支持向量机的特例,因而通常的支持向量机算法并不区分是否线性可分。至此,我按照从简单到复杂的顺序,向你介绍了支持向量机三种模型的原理。在实际的应用中,对最优化目标函数的求解需要应用到最优化的理论,在这里对其思路加以简单说明。如果将支持向量机的最优化作为原始问题,应用最优化理论中的拉格朗日对偶性,可以通过求解其对偶问题得到原始问题的最优解。三种模型的参数学习都可以转化为对偶问题的求解。
在算法实现的过程中,支持向量机会遇到在大量训练样本下,全局最优解难以求得的尴尬。目前,高效实现支持向量机的主要算法是 SMO 算法(Sequential Minimal Optimization,序列最小最优化)。支持向量机的学习问题可以形式化为凸二次规划问题的求解,SMO 算法的特点正是不断将原始的二次规划问题分解为只有两个变量的二次规划子问题,并求解子问题的解析解,直到所有变量满足条件为止。支持向量机的一个重要性质是当训练完成后,最终模型只与支持向量有关,这也是“支持向量机”这个名称的来源。正如发明者瓦普尼克所言:支持向量机这个名字强调了这类算法的关键是如何根据支持向量构建出解,算法的复杂度也主要取决于支持向量的数目。
在无线通信中,有一种广受欢迎的“MIMO”传输技术。MIMO 的全称是多输入多输出(Multiple Input Multiple Output),其早期配置是在发送端和接收端同时布置多个发射机和多个接收机,每个发射机发送相同的信号副本,而每个接收机则接收到来自多个发射机的不同信号,这些信号经历的衰减是相互独立的。这样一来,在接收端多个信号同时被严重衰减的概率就会以指数形式减小,通过获得分集增益带来误码率的下降与信道容量的提升。无线通信中的分集思想在机器学习中的对应就是集成学习。集成学习正是使用多个个体学习器来获得比每个单独学习器更好的预测性能。
监督学习的任务是通过假设空间搜索来找到能够对特定问题给出良好预测的假设。但问题是即使这样的假设存在,能否找到也在两可之间。因而集成学习的作用就是将多个可以得到假设整合为单个更好的假设,其一般结构是先产生一组个体学习器,再使用某种策略将它们加以整合。每个组中的个体学习器如果属于同一类型(比如都是线性回归或者都是决策树),形成的就是同质集成;相应地,由不同类型学习器得到的集成则称为异质集成。直观来看,性能优劣不一的个体学习器放在一块儿可能产生的是更加中庸的效果,即比最差的要好,也比最好的要差。那么集成学习如何实现“1 + 1 > 2”呢?这其实是对个体学习器提出了一些要求。
一方面,个体学习器的性能要有一定的保证。如果每个个体学习器的分类精度都不高,在集成时错误的分类结果就可能占据多数,导致集成学习的效果甚至会劣于原始的个体学习器,正如俗语所言“和臭棋手下棋,越下越臭”。另一方面,个体学习器的性能要有一定的差异,和而不同才能取得进步。多样性(diversity)是不同的个体学习器性能互补的前提,这恰与 MIMO 中分集(diversity)的说法不谋而合。
在 MIMO 中,一个重要的前提条件是不同信号副本传输时经历的衰减要相互独立。同样的原则在机器学习中体现为个体学习器的误差相互独立。但由于个体学习器是为了解决相同问题训练出来的,要让它们的性能完全独立着实是勉为其难。尤其是当个体学习器的准确性较高时,要获得多样性就不得不以牺牲准确性作为代价。由此,集成学习的核心问题在于在多样性和准确性间做出折中,进而产生并结合各具优势的个体学习器。个体学习器的生成方式很大程度上取决于数据的使用策略。根据训练数据使用方法的不同,集成学习方法可以分为两类:个体学习器间存在强依赖关系因而必须串行生成的序列化方法,和个体学习器之间不存在强依赖关系因而可以同时生成的并行化方法。
序列化方法中的数据使用机制被称为提升(Boosting),其基本思路是对所有训练数据进行多次重复应用,每次应用前需要对样本的概率分布做出调整,以达到不同的训练效果。与 Boosting 相比,并行化方法中的数据使用机制是将原始的训练数据集拆分成若干互不交叠的子集,再根据每个子集独立地训练出不同的个体学习器。这种方法被称为自助聚合(Bootstrap AGgregation),简称打包(Bagging)。在 Bagging 机制中,不同个体学习器之间的多样性容易得到保证;但由于每个个体学习器只能使用一小部分数据进行学习,其效果就容易出现断崖式下跌。
在基于训练数据集生成样本的子集时,Bagging 采用的是放回抽样的策略,即某些样本可能出现在不同的子集之中,而另外某些样本可能没有出现在任何子集之内。计算未被抽取概率的极限可以得到,放回抽样会导致 36.8% 的训练数据没有出现在采样数据集中。这些未使用的数据没有参与个体学习器的训练,但可以作为验证数据集,用于对学习器的泛化性能做出包外估计,包外估计得到的泛化误差已被证明是真实值的无偏估计。典型的序列化学习算法是自适应提升方法(Adaptive Boosting),人送绰号 AdaBoost。在解决分类问题时,提升方法遵循的是循序渐进的原则。先通过改变训练数据的权重分布,训练出一系列具有粗糙规则的弱个体分类器,再基于这些弱分类器进行反复学习和组合,构造出具有精细规则的强分类器。从以上的思想中不难看出,AdaBoost 要解决两个主要问题:训练数据权重调整的策略和弱分类器结果的组合策略。
在训练数据的权重调整上,AdaBoost 采用专项整治的方式。在每一轮训练结束后,提高分类错误的样本权重,降低分类正确的样本权重。因此在下一轮次的训练中,弱分类器就会更加重视错误样本的处理,从而得到性能的提升。这就像一个学生在每次考试后专门再把错题重做一遍,有针对性地弥补不足。虽然训练数据集本身没有变化,但不同的权重使数据在每一轮训练中发挥着不同的作用。在 AdaBoost 的弱分类器组合中,每一轮得到的学习器结果都会按照一定比例叠加到前一轮的判决结果,并参与到下一轮次权重调整之后的学习器训练中。当学习的轮数达到预先设定的数目 T 时,最终分类器的输出就是 T 个个体学习器输出的线性组合。每个个体学习器在最终输出的权重与其分类错误率相关,个体学习器中的分类错误率越低,其在最终分类器中起到的作用就越大。但需要注意的是,所有个体学习器权重之和并不必须等于 1。
根据以上的主要策略,可以归纳出算法的特点。随着训练过程的深入,弱学习器的训练重心逐渐被自行调整到的分类器错误分类的样本上,因而每一轮次的模型都会根据之前轮次模型的表现结果进行调整,这也是 AdaBoost 的名字中“自适应”的来源。前面介绍的是 AdaBoost 的执行策略。换个视角来看,AdaBoost 可以视为使用加法模型,以指数函数作为损失函数,使用前向分步算法的二分类学习方法。加法模型反映出 AdaBoost 以个体学习器的线性组合作为最终分类器的特性。在这个模型下求解指数型损失函数的最小值是个复杂的问题,但可以通过每次只学习线性组合其中的一项来简化其处理,这种方法就是前向分步算法。前向分步算法注意学习基函数的过程和 AdaBoost 注意学习个体学习器的过程是一致的。
典型的并行化学习方法是随机森林方法。正所谓“独木不成林”,随机森林就是对多个决策树模型的集成。“随机”的含义体现在两方面:一是每个数据子集中的样本是在原始的训练数据集中随机抽取的,这在前文中已有论述;二是在决策树生成的过程中引入了随机的属性选择。在随机森林中,每棵决策树在选择划分属性时,首先从结点的属性集合中随机抽取出包含 k 个属性的一个子集,再在这个子集中选择最优的划分属性生成决策树。为什么要执行随机的属性选择呢?其目的在于保证不同基决策树之间的多样性。如果某一个或几个属性对输出的分类结果有非常强的影响,那么很可能所有不同的个体决策树都选择了这些属性,这将导致不同子集上训练出个体决策树呈现出众口一辞的同质性,对原始训练样本的有放回随机抽取也就失去了意义。在这个意义上,随机特征选取是对集成学习算法中多样性的一重保护措施。
在合成策略上,随机森林通常采用少数服从多数的策略,选择在个体决策树中出现最多的类别标记作为最终的输出结果。当数据较多时,也可以采用更加强大的学习法,即通过另一个单独的学习器实现复杂合成策略的学习。随机森林是罕有的具有强通用性的机器学习方法,能够以较小的计算开销在多种现实任务中展现出强大的性能。数据使用机制的不同在泛化误差的构成上也有体现。
以 Boosting 方法为代表的序列化方法使用了全体训练数据,并根据每次训练的效果不断迭代以使损失函数最小化,因而可以降低平均意义上的偏差,能够基于泛化能力较弱的学习器构建出较强的集成。以 Bagging 方法为代表的并行化方法则利用原始训练数据生成若干子集,因而受异常点的影响较小,对在每个子集上训练出的不完全相关的模型取平均也有助于平衡不同模型之间的性能,因而可以一定程度上降低方差。
20 世纪 40 年代,美国心理学家罗伯特·泰昂和雷蒙德·卡泰尔借鉴人类学中的研究方法,提出“聚类分析”的概念,通过从相关矩阵中提取互相关的成分进行性格因素的研究。随着时间的推移,聚类分析的应用范围越来越广泛,逐渐演化成一种主要的机器学习方法。聚类分析是一种无监督学习方法,其目标是学习没有分类标记的训练样本,以揭示数据的内在性质和规律。具体来说,聚类分析要将数据集划分为若干个互不相交的子集,每个子集中的元素在某种度量之下都与本子集内的元素具有更高的相似度。
用这种方法划分出的子集就是“聚类”(或称为“簇”),每个聚类都代表了一个潜在的类别。分类和聚类的区别也正在于此:分类是先确定类别再划分数据;聚类则是先划分数据再确定类别。聚类分析本身并不是具体的算法,而是要解决的一般任务,从名称就可以看出这项任务的两个核心问题:一是如何判定哪些样本属于同一“类”,二是怎么让同一类的样本“聚”在一起。解决哪些样本属于同一“类”的问题需要对相似性进行度量。无论采用何种划定标准,聚类分析的原则都是让类内样本之间的差别尽可能小,而类间样本之间的差别尽可能大。度量相似性最简单的方法就是引入距离测度,聚类分析正是通过计算样本之间的距离来判定它们是否属于同一个“类”。根据线性代数的知识,如果每个样本都具有 N 个特征,那就可以将它们视为 N 维空间中的点,进而计算不同点之间的距离。
作为数学概念的距离需要满足非负性(不小于 0)、同一性(任意点与其自身之间的距离为 0)、对称性(交换点的顺序不改变距离)、直递性(满足三角不等式)等性质。在聚类分析中常用的距离是“闵可夫斯基距离”,其定义为

式中的 p 是个常数。当 p=2 时,闵可夫斯基距离就变成了欧式距离,也就是通常意义上的长度。确定了“类”的标准之后,接下来就要考虑如何让同一类的样本“聚”起来,也就是聚类算法的设计。目前,公开发表的聚类算法已经超过了 100 种,但无监督学习的特性决定了不可能存在通用的聚类算法。根据应用场景的差别,不同算法在组成聚类的概念以及有效找到聚类的方法上也会有所区别。针对某种模型设计的算法在其他模型的数据集上表现的一塌糊涂也不是什么新鲜事。接下来我介绍的就是几类最主要的聚类算法及其实例。
层次聚类又被称为基于连接的聚类,其核心思想源于样本应当与附近而非远离的样本具有更强的相关性。由于聚类生成的依据是样本之间的距离,因而聚类的特性可以用聚类内部样本之间的距离尺度来刻画。聚类的划分是在不同的距离水平上完成的,划分过程就可以用树状图来描述,这也解释了 " 层次聚类 " 这个名称的来源。层次聚类对数据集的划分既可以采用自顶向下的拆分策略,也可以采用自底向上的会聚策略,后者是更加常用的方法。在采用会聚策略的层次聚类算法中,数据集中的每个样本都被视为一个初始聚类。算法每执行一步,就将距离最近的两个初始聚类合并,这个过程将一直重复到合并后的数目达到预设数为止。
根据距离计算方式的不同,会聚算法可以分为单链接算法、全链接算法和均链接算法等。单链接算法利用的是最小距离,它由两个不同聚类中相距最近的样本决定;全链接算法利用的是最大距离,它由两个不同聚类中相距最远的样本决定;均链接算法利用的是平均距离,它由两个不同聚类中的所有样本共同决定。虽然存在特定的快速算法,但会聚策略的计算复杂度依然较高。相比之下,拆分策略更加复杂,在此就不做介绍了。原型聚类又被称为基于质心的聚类,其核心思想是每个聚类都可以用一个质心表示。原型聚类将给定的数据集初始分裂为若干聚类,每个聚类都用一个中心向量来刻画,然后通过反复迭代来调整聚类中心和聚类成员,直到每个聚类不再变化为止。
k 均值算法是典型的原型聚类算法,它将聚类问题转化为最优化问题。具体做法是先找到 k 个聚类中心,并将所有样本分配给最近的聚类中心,分配的原则是让所有样本到其聚类中心的距离平方和最小。显然,距离平方和越小意味着每个聚类内样本的相似度越高。但是这个优化问题没有办法精确求解,因而只能搜索近似解。k 均值算法就是利用贪心策略,通过迭代优化来近似求解最小平方和的算法。k 均值算法的计算过程非常直观。首先从数据集中随机选取 k 个样本作为 k 个聚类各自的中心,接下来对其余样本分别计算它们到这 k 个中心的距离,并将样本划分到离它最近的中心所对应的聚类中。当所有样本的聚类归属都确定后,再计算每个聚类中所有样本的算术平均数,作为聚类新的中心,并将所有样本按照 k 个新的中心重新聚类。这样,“取平均 - 重新计算中心 - 重新聚类”的过程将不断迭代,直到聚类结果不再变化为止。
大多数 k 均值类型的算法需要预先指定聚类的数目 k,这是算法为人诟病的一个主要因素。此外,由于算法优化的对象是每个聚类的中心,因而 k 均值算法倾向于划分出相似大小的聚类,这会降低聚类边界的精确性。分布聚类又被称为基于概率模型的聚类,其核心思想是假定隐藏的类别是数据空间上的一个分布。在分布聚类中,每个聚类都是最可能属于同一分布的对象的集合。这种聚类方式类似于数理统计中获得样本的方式,也就是每个聚类都由在总体中随机抽取独立同分布的样本组成。其缺点则在于无法确定隐含的概率模型是否真的存在,因而常常导致过拟合的发生。
聚类分析的任务原本是将数据划分到不同的聚类中,可如果我们将样本看作观察值,将潜在类别看作隐藏变量,那么就可以逆向认为数据集是由不同的聚类产生的。在这个前提下,基于概率模型的聚类分析的任务是推导出最可能产生出已有数据集的 k 个聚类,并度量这 k 个聚类产生已有数据集的似然概率。基于概率模型的聚类实质上就是进行参数估计,估计出聚类的参数集合以使似然函数最大化。期望极大算法(Expectation Maximization algorithm)是典型的基于概率模型的聚类方法。EM 算法是一种迭代算法,用于含有不可观察的隐变量的概率模型中,在这种模型下对参数做出极大似然估计,因而可以应用在聚类分析之中。
EM 算法执行的过程包括“期望”和“最大化”两个步骤。将待估计分布的参数值随机初始化后,期望步骤利用初始参数来估计样本所属的类别;最大化步骤利用估计结果求取当似然函数取得极大值时,对应参数值的取值。两个步骤不断迭代,直到收敛为止。密度聚类又被称为基于密度的聚类,其核心思想是样本分布的密度能够决定聚类结构。每个样本集中分布的区域都可以看作一个聚类,聚类之间由分散的噪声点区分。密度聚类算法根据样本密度考察样本间的可连接性,再基于可连接样本不断扩展聚类以获得最终结果。
最流行的基于密度的聚类方法是利用噪声的基于密度的空间聚类(Density-Based Spatial Clustering of Applications with Noise),简称 DBSCAN。DBSCAN 通过将距离在某一个阈值之内的点连接起来而形成聚类,但连接的对象只限于满足密度标准的点。ϵ - 邻域这一概念给出的对邻域的限制,密度的可连接性则通过密度直达关系、密度可达关系、密度相连关系等一系列标准定义,根据这些概念形成的聚类就是由密度可达关系导出的最大的密度相连样本集合。根据思想的不同,聚类方法主要包括以上的四种类型,每种类型上也有其典型算法。
正所谓“物以类聚,人以群分”,聚类分析的一个重要应用就是用户画像。在商业应用中判别新用户的类型时,往往要先对用户进行聚类分析,再根据聚类分析的结果训练分类模型,用于用户类型的判别。聚类使用的特征通常包括人口学变量、使用场景、行为数据等。
毛主席在《矛盾论》中提出了主要矛盾和次要矛盾的概念:“研究任何过程,如果是存在着两个以上矛盾的复杂过程的话,就要用全力找出它的主要矛盾。”这种哲学观点也可以用来指导机器学习。一个学习任务通常会涉及样本的多个属性,但并非每个属性在问题的解决中都具有同等重要的地位,有些属性可能举足轻重,另一些则可能无关紧要。根据凡事抓主要矛盾的原则,对举足轻重的属性要给予足够的重视,无关紧要的属性则可以忽略不计,这在机器学习中就体现为降维的操作。
主成分分析是一种主要的降维方法,它利用正交变换将一组可能存在相关性的变量转换成一组线性无关的变量,这些线性无关的变量就是主成分。多属性的大样本无疑能够提供更加丰富的信息,但也不可避免地增加了数据处理的工作量。更重要的是,多数情况下不同属性之间会存在相互依赖的关系,如果能够充分挖掘属性之间的相关性,属性空间的维度就可以降低。在现实生活中少不了统计个人信息的场合,而在个人信息的表格里通常会包括“学历”和“学位”两个表项。因为学位和学历代表着两个独立的过程,因此单独列出是没有问题的。但在我国现行的惯例下,这两者通常会一并取得。两者之间的相关性足以让我们根据一个属性的取值去推测另一个属性的取值,因此只要保留其中一个就够了。
但这样的推测是不是永远准确呢?也不是。如果毕业论文的答辩没有通过,就会出现只有学历而没有学位的情形;对于在职研究生来说,只有学位没有学历的情形也不稀奇。这说明如果将学历和学位完全等同,就会在这些特例上出现错误,也就意味着信息的损失。这是降维操作不可避免的代价。以上的例子只是简单的定性描述,说明了降维的出发点和可行性。在实际的数据操作中,主成分分析解决的就是确定以何种标准确定属性的保留还是丢弃,以及度量降维之后的信息损失。
从几何意义来看,主成分分析是要将原始数据拟合成新的 n 维椭球体,这个椭球体的每个轴代表着一个主成分。如果椭球体的某个轴线较短,那么该轴线所代表的主成分的方差也很小。在数据集的表示中省略掉该轴线以及其相应的主成分,只会丢失相当小的信息量。具体说来,主成分分析遵循如下的步骤:
数据规范化:对 m 个样本的相同属性值求出算术平均数,再用原始数据减去平均数,得到规范化后的数据;协方差矩阵计算:对规范化后的新样本计算不同属性之间的协方差矩阵,如果每个样本有 n 个属性,得到的协方差矩阵就是 n 维方阵;特征值分解:求解协方差矩阵的特征值和特征向量,并将特征向量归一化为单位向量;降维处理:将特征值按照降序排序,保留其中最大的 k 个,再将其对应的 k 个特征向量分别作为列向量组成特征向量矩阵;数据投影:将减去均值后的 m×n 维数据矩阵和由 k 个特征向量组成的 n×k 维特征向量矩阵相乘,得到的 m×k 维矩阵就是原始数据的投影。
经过这几步简单的数学运算后,原始的 n 维特征就被映射到新的 k 维特征之上。这些相互正交的新特征就是主成分。需要注意的是,主成分分析中降维的实现并不是简单地在原始特征中选择一些保留,而是利用原始特征之间的相关性重新构造出新的特征。为什么简单的数学运算能够带来良好的效果呢?从线性空间的角度理解,主成分分析可以看成将正交空间中的样本点以最小误差映射到一个超平面上。如果这样的超平面存在,那它应该具备以下的性质:一方面,不同样本点在这个超平面上的投影要尽可能地分散;另一方面,所有样本点到这个超平面的距离都应该尽可能小。
样本点在超平面上的投影尽可能分散体现出的是最大方差原理。在信号处理理论中,当信号的均值为零时,方差反映的就是信号的能量,能量越大的信号对抗噪声和干扰的能力也就越强。而让投影后样本点的方差最大化,就是要让超平面上的投影点尽可能地分散。如果原始信号的投影都集中在超平面的同一个区域,不同的信号之间就会难以区分。在数学上,投影后所有样本点的方差可以记作
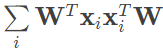
式中每个 n 维向量 xi 都代表具有 n 个属性的样本点,W 则是经过投影变换后得到的新坐标系。最大方差要求的正是求解最优的 W,以使前面的方差表达式,也就是对应矩阵所有对角线元素的和最大化。经过数学处理后可以得到,使方差最大化的 W 就是由所有最大特征值的特征向量组合在一起形成的,也就是主成分分析的解。
在线性回归中,我向你介绍了最小均方误差的概念,主成分分析的最优性也可以从这个角度来审视。所有样本点到这个超平面的距离都应该尽可能小,意味着这些点到平面距离之和同样最小。原始样本点在低维超平面上的投影的表达式是
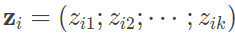
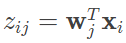
其中每个zij是原始样本点 xi 在低维超平面上第 j 维上的坐标。因而,原始样本点和在投影超平面上重构出的样本点之间的距离可以表示为
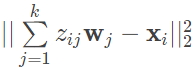
在整个训练集上对距离求和并最小化,求出的解就是最小均方误差意义下的最优超平面。经过数学处理后可以得到,使均方误差最小化的 W 就是由所有最大特征值的特征向量组合在一起形成的,同样是主成分分析的解。
在主成分分析中,保留的主成分的数目是由用户来确定的。一个经验方法是保留所有大于 1 的特征值,以其对应的特征向量来做坐标变换。此外,也可以根据不同特征值在整体中的贡献,以一定比例进行保留。具体方法是计算新数据和原始数据之间的误差,令误差和原始数据能量的比值小于某个预先设定的阈值。主成分分析能够对数据进行降维处理,保留正交主成分中最重要的部分,在压缩数据的同时最大程度地保持了原有信息。主成分分析的优点在于完全不受参数的限制,即不需要先验的参数或模型对计算过程的人为干预,分析的结果只与数据有关。但有得必有失,这个特点的另一面是即使用户具有对训练数据集的先验知识,也没有办法通过参数化等方法加以利用。
除此之外,由于主成分分析中利用的是协方差矩阵,因而只能去除线性相关关系,对更加复杂的非线性相关性就无能为力了。解决以上问题的办法是将支持向量机中介绍过的核技巧引入主成分分析,将先验知识以非线性变换的形式体现,因而扩展了主成分分析的应用范围。主成分分析实现降维的前提是通过正交变换对不同属性进行去相关。另一种更加直观的降维方式则是直接对样本的属性做出筛选,这种降维方法就是“特征选择”。特征选择的出发点在于去除不相关的特征往往能够降低学习任务的难度,它和主成分分析共同构成了处理高维数据的两大主流技术。
特征选择与特征提取不同。特征提取是根据原始特征的功能来创建新特征,特征选择则是选取原始特征中的一个子集用于学习任务。特征选择通常用于特征较多而样本较少的问题中,使用特征选择技术的核心前提是数据包含许多冗余和不相关特征,它们可以在不引起信息损失的情况下被移除。特征选择的主要应用场景包括书面文本分析和 DNA 微阵列数据的分析,这些场景下样本的数目通常数以百计,每个样本却可能包含成千上万的特征。特征选择算法是搜索新的特征子集和对搜索结果进行评估两个步骤的组合。最简单的选择方法是测试每个可能的特征子集,从中找出错误率最小的特征子集。这是一个详尽的空间搜索,但子集的数目会随着特征数目的增加以指数方式增加,特征稍多时就无法进行。相比之下,一种可行的做法是产生一个特征子集并评价其效果,根据评价结果再产生新的特征子集并继续评价,直到无法找到更好的候选子集为止。
根据评价方式的不同,特征选择算法主要可以分为包裹法、过滤法和嵌入法三类。包裹法使用预测模型来评价特征子集。每个新的特征子集都用来训练一个模型,并在验证数据集上进行测试,模型在验证数据集上的错误率也就是该子集的分数。由于包裹法为每个子集都要训练一个新的模型,因而其计算量较大,但它的优点是能够找到适用特定模型的最佳特征子集。与包裹法不同,过滤法先对数据集进行特征选择,也就是对初始特征进行过滤,再用过滤后的特征来训练模型。过滤法的计算负荷要小于包裹法,但由于特征子集和预测模型之间并没有建立对应关系,因而其性能也会劣于包裹法。但另一方面,过滤法得到的特征子集具有更强的通用性,也有助于揭示不同特征之间的关系。许多过滤器提供的不是一个明确的最佳功能子集,而是不同特征的排名,因而过滤法可以作为包裹法的预处理步骤来使用。
嵌入法结合了包裹法和过滤法的思路,将特征选择和模型训练两个过程融为一体,使学习器在训练过程中自动完成特征选择。其典型的方法是引入 L1 范数作为正则项的 LASSO 方法。LASSO 方法的原理在线性回归中已经做过介绍,在此不做重复。一般来说,嵌入法的计算复杂度在包裹法和过滤法之间。
接下来,我将分享人工智能---人工神经网络




发表评论